Sole Automation Engineer · AI Workflow Architect
n8n Content Pipeline — Topic to Published SEO Article in Under 4 Minutes
Self-hosted n8n pipeline triggered by one Telegram command. Six stages: parallel research, SEO analysis, multi-agent Writer→Critic→Refiner loop, Claude QA, final scoring.
Topic-to-publish dropped from ~18 hours to 3–4 minutes; replaced 15+ hrs/week of manual work.
n8n Content Pipeline: Topic to Published SEO Article in Under 4 Min My role. n8n Automation Developer & AI Workflow Architect
Project description.
The problem: a content team was spending 15–20 hours per article on research, drafting, editing, and QA — with inconsistent quality. What I built: a self-hosted n8n pipeline triggered by one Telegram command. Six stages run end-to-end — parallel research (SearXNG + Firecrawl), DataForSEO keyword analysis, a multi-agent Writer→Critic→Refiner loop, Claude Sonnet QA, and a final scoring pass. Each stage has quality gates and retry logic. Result: topic-to-publish dropped from ~18 hours to 3–4 minutes, replacing 15+ hrs/week of manual work. Stack: n8n, Claude, OpenAI, Firecrawl, Docker. Skills and deliverables
n8n Automation Claude
n8n Content Pipeline: Topic to Published SEO Article in Under 4 Minutes
Role: Sole Automation Engineer
Stack: n8n (self-hosted), Docker, PostgreSQL, SearXNG, Firecrawl, OpenAI, OpenRouter (Claude), DataForSEO, Telegram Bot API
Status: Functional prototype — core pipeline works end-to-end, some production gaps remain (noted below)
What It Does
An automated content pipeline that takes a Skool community name and URL as input and produces a fully researched, SEO-optimized, editorially reviewed article — delivered as Markdown and HTML files via Telegram — in under 4 minutes.
The system handles everything: web research, page scraping, SEO keyword analysis, AI-powered writing with an iterative critic/refiner loop, multi-layer quality assurance, and file delivery. No human touches the content between trigger and output.
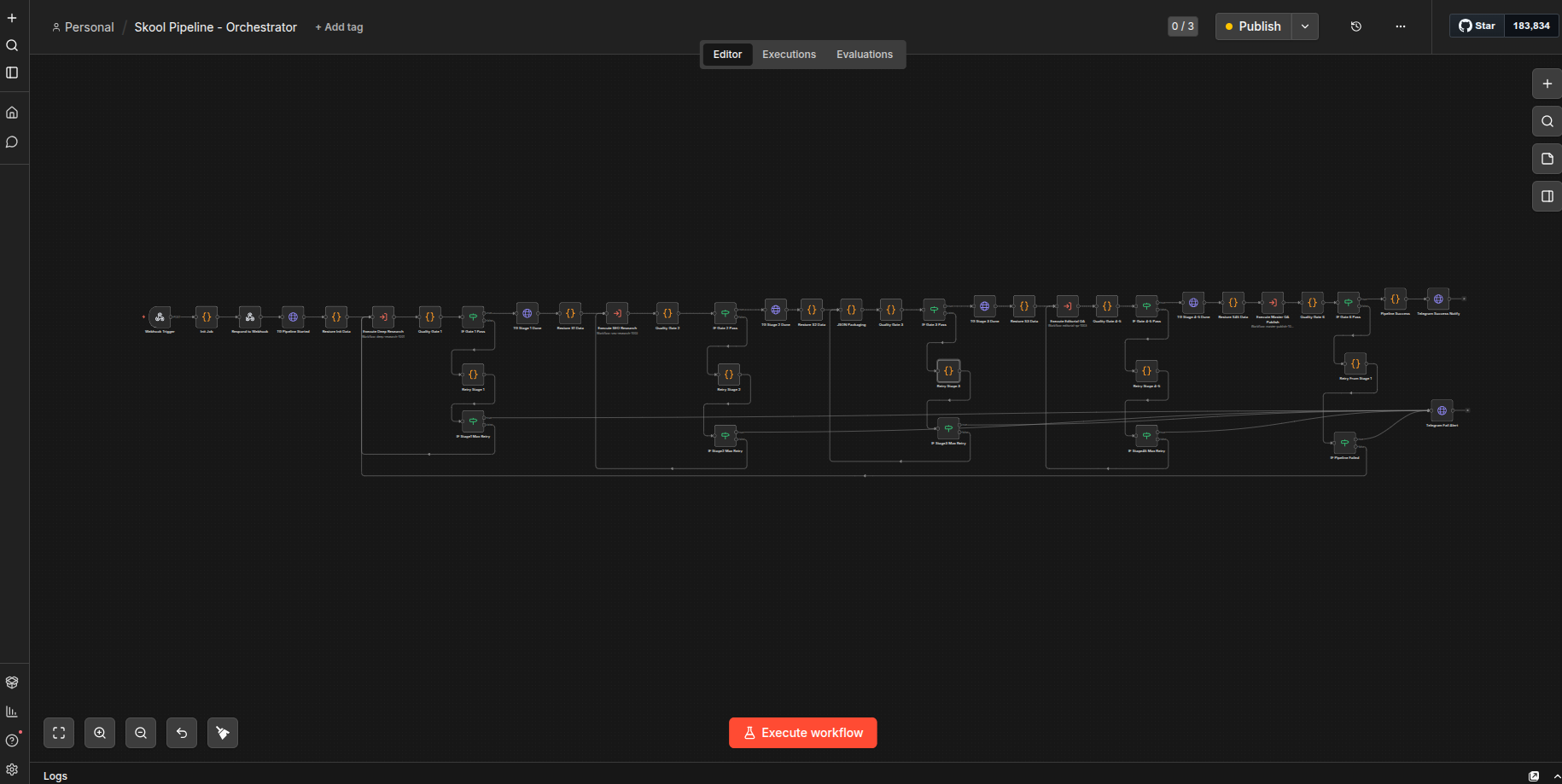
Architecture Overview
Trigger (Webhook or Telegram Bot)
│
├── Stage 1: Deep Research (SearXNG + Firecrawl + GPT-4o)
│ └── Quality Gate → retry up to 2x on failure
│
├── Stage 2: SEO Research (DataForSEO + GPT-4o)
│ └── Quality Gate → retry up to 2x on failure
│
├── Stage 3: Data Packaging (merge research + SEO into structured JSON)
│ └── Quality Gate → validate required fields
│
├── Stage 4-5: Editorial + QA (Claude Sonnet via OpenRouter)
│ ├── Writer → Critic → Score Check
│ │ └── Loop: Refiner → Critic (up to 3 iterations)
│ ├── Plagiarism Check
│ ├── Fact Check
│ └── Word Count + Tone Analysis
│
└── Stage 6: Master QA + Publish (Claude Sonnet via OpenRouter)
├── Final 5-dimension scoring
├── Generate Markdown (YAML frontmatter) + HTML (styled)
├── Send files via Telegram
└── Quality Gate → retry full pipeline up to 2x on failure
Six n8n workflows orchestrated by a parent workflow, plus a standalone Telegram bot workflow for triggering via chat.
Workflow Breakdown
| File | Workflow | What It Does |
|---|---|---|
01_orchestrator.json | Orchestrator | Receives webhook, coordinates all stages, manages quality gates, retries, and Telegram notifications |
02_deep_research.json | Deep Research | 7 parallel SearXNG searches + Firecrawl page scraping + GPT-4o synthesis |
03_seo_research.json | SEO Research | DataForSEO keyword volumes + SERP analysis + GPT-4o keyword clustering |
04_editorial_qa.json | Editorial QA | Writer/Critic/Refiner loop + plagiarism + fact-check + tone/word-count QA |
05_master_publish.json | Master Publish | Final scoring, Markdown + HTML generation, Telegram file delivery |
06_telegram_bot.json | Telegram Bot | Polls for /review commands, triggers the pipeline via internal webhook |
00_init_db.sql | Database Schema | PostgreSQL schema for job persistence (defined but not wired into workflows) |
Infrastructure — Fully Self-Hosted
Everything runs in Docker via a single docker-compose.yml. No external SaaS dependencies for scraping or search — only API keys for AI models and SEO data.
10 containers in the stack:
| Service | Image | Purpose |
|---|---|---|
| n8n | n8nio/n8n:latest | Workflow engine |
| PostgreSQL | pgvector/pgvector:0.6.2-pg15 | n8n backend database |
| SearXNG | searxng/searxng:latest | Privacy-respecting meta-search engine |
| SearXNG Redis | valkey/valkey:alpine | SearXNG cache |
| Firecrawl API | ghcr.io/firecrawl/firecrawl:latest | Web scraping with JS rendering |
| Firecrawl Playwright | ghcr.io/firecrawl/playwright-service:latest | Headless browser for Firecrawl |
| Firecrawl Redis | redis:alpine | Firecrawl job queue |
| Firecrawl RabbitMQ | rabbitmq:3-management | Firecrawl message broker |
| Firecrawl PostgreSQL | ghcr.io/firecrawl/nuq-postgres:latest | Firecrawl storage |
All services communicate over a private Docker bridge network. Health checks ensure startup ordering.
AI Model Strategy
| Task | Model | Why |
|---|---|---|
| Research synthesis | GPT-4o (OpenAI) | Fast, good at structured extraction and summarization |
| SEO keyword clustering | GPT-4o (OpenAI) | Reliable JSON output for analytical tasks |
| Article writing | Claude Sonnet (OpenRouter) | Stronger long-form prose, better editorial voice |
| Critic scoring | Claude Sonnet (OpenRouter) | Nuanced evaluation with structured JSON scores |
| Refinement | Claude Sonnet (OpenRouter) | Addresses critic feedback while preserving voice |
| QA checks | Claude Sonnet (OpenRouter) | Plagiarism, fact-check, tone analysis |
| Final master scoring | Claude Sonnet (OpenRouter) | 5-dimension quality assessment |
The split is deliberate: GPT-4o handles the structured data extraction where speed matters; Claude handles the editorial work where writing quality matters.
Key Engineering Decisions
Quality Gates with Retry Logic
Every stage has a quality gate. If a gate fails, the pipeline retries that stage (up to 2 attempts). If Stage 6 (final scoring) fails, the entire pipeline restarts from Stage 1 with failure context appended so subsequent attempts can compensate.
Writer/Critic/Refiner Loop
The editorial stage doesn't just generate once. It runs an iterative loop:
- Writer produces a draft
- Critic scores it across multiple dimensions (returns JSON)
- If average score < 5/10, the Refiner rewrites based on critic feedback
- Loop repeats up to 3 times
- A "last chance refiner" runs if all iterations are exhausted
State Restoration Pattern
Telegram notification nodes sit in the middle of the pipeline for real-time progress updates. Since n8n passes data linearly, dedicated "Restore Data" nodes re-inject the correct pipeline state after every Telegram side-channel call, preventing data corruption downstream.
Self-Hosted Search and Scraping
SearXNG and Firecrawl are self-hosted specifically to avoid rate limits and per-request costs from third-party scraping APIs. The tradeoff is infrastructure complexity (5 extra containers), but it gives unlimited scraping at zero marginal cost.
Skills Demonstrated
- n8n workflow design — sub-workflow orchestration, webhook triggers, quality gates, retry patterns, state management across branching paths
- Multi-model AI orchestration — routing different task types to appropriate LLMs, structured JSON prompting, fallback parsing
- Docker infrastructure — 10-service compose stack with health checks, dependency ordering, shared networking, volume persistence
- SEO automation — DataForSEO API integration, keyword volume analysis, SERP competitor analysis, intent classification
- Web scraping at scale — Firecrawl with Playwright for JS-rendered pages, SearXNG for aggregated search results
- Editorial automation — iterative critic/refiner pattern, multi-dimensional scoring, plagiarism and fact-checking
- Bot development — Telegram bot with command parsing, polling, and bidirectional notifications
- Error handling —
continueOnFailon external calls, JSON parse fallbacks, defensive data reads, failure context propagation
How to Run It
# 1. Clone and configure
cp .env.example .env
# Fill in: OPENAI_API_KEY, OPENROUTER_API_KEY, DATAFORSEO_LOGIN,
# DATAFORSEO_PASSWORD, TELEGRAM_BOT_TOKEN, TELEGRAM_CHAT_ID,
# POSTGRES_PASSWORD, N8N_USER, N8N_PASSWORD
# 2. Start the stack
docker-compose up -d
# 3. Import workflows into n8n (http://localhost:5678)
# Import in order: 02, 03, 04, 05, 06, then 01
# Ensure workflow IDs match the hardcoded references
# 4. Activate all workflows
# 5. Trigger via webhook
curl -X POST http://localhost:5678/webhook/skool-pipeline \
-H "Content-Type: application/json" \
-d '{"community_name": "Skool Games", "founder_name": "Sam Ovens", "community_url": "https://www.skool.com/games"}'
# Or trigger via Telegram: /review Skool Games, Sam Ovens, https://www.skool.com/games
Tech Stack Summary
| Category | Technology |
|---|---|
| Workflow Engine | n8n (self-hosted) |
| Infrastructure | Docker Compose (10 containers) |
| Database | PostgreSQL 15 (pgvector) |
| Search | SearXNG (self-hosted meta-search) |
| Scraping | Firecrawl + Playwright (self-hosted) |
| AI — Research | OpenAI GPT-4o |
| AI — Editorial | Anthropic Claude Sonnet (via OpenRouter) |
| SEO Data | DataForSEO (keyword volumes + SERP) |
| Message Queue | RabbitMQ, Redis (Valkey) |
| Bot Interface | Telegram Bot API |
| Output Formats | Markdown (YAML frontmatter), HTML (styled CSS) |
Built as a freelance project. The pipeline consistently produces 1,500–2,500 word SEO articles from a single community URL input, with research, keyword targeting, and editorial QA — all automated, all under 4 minutes.
Project gallery
Tap any image to view full size.